Most people didn't notice, but there was a new feature added to the ZDLRA called "store and forward".
Documentation on how to implement it is in the "ZDLRA Administration Guide" under the topic of implementing high availability strategies.
Within that you will find the section on
ZDLRA offers the customer the ability to send backups (Redo logs and Level 1 backups) to an alternate ZDLRA location. This provides an efficient HA solution for this information if the primary ZDLRA can't be reached.
Now in order to explain how Store and Forward works, first lets take a look at the architecture.
- We have a database we are backing up called "PROTDB"
- We have 2 different ZDLRA's. Store and Forward requires a minimum of 2 ZDLRA appliances in a datacenter. In this case some of the databases have one of their ZDLRAs as their backup target and the remaining databases have the other ZDLRA as their backup target.
- For databases backing up to ZDLRA #1 "RA01" will be the preferred ZDLRA that their Level 1 backups and the redo log stream will go to. ZDLRA #2 "RA02" will be the alternate ZDLRA that Level 1 backups and the redo log stream will go to in the event of an outage communicating with preferred ZDLRA "RA01".
- The reverse will be true for databases backing up to ZDLRA #2 with the alternate being ZDLRA #1
NOTE : A database has to be unique within a ZDLRA. What this means is that the alternate ZDLRA cannot already used for replication or to backup a dataguard copy of the same database.

Now that we have defined the architecture let's go through the pieces that make up the store-and-forward methodology.
First however I will define what I mean by "Upstream" and "downstream".
UPSTREAM - This is the ZDLRA that sends replicated backup copies.
DOWNSTREAM - This is the ZDLRA that receives the replicated backup copies.
A ZDLRA can act as both an UPSTREAM and a DOWNSTREAM. This is common when a customer has 2 active datacenters. Each ZDLRA acts as both an Upstream (receiving backups directly) and as a Downstream (receiving replicated backups).
In the store-and-forward methodology backups are sent to the Downstream as the primary, and the Upstream as the Alternate. This allows for backups to replicate from the Alternate (Upstream) to the Primary (Downstream). This will be explained as you walk through flow.
Configuring Store-and-Forward
1) Configure "RA01" to be the down stream replicated pair of RA02.
2) Ensure that the protected database ("PROTDB") is added to policies on both RAs (this process is described in the 12.2 admin guide)
3) Ensure "PROTDB" has a wallet entries for both RAs, and that it the database is properly registered in both RMAN catalogs (using the admin guide).
3) Configure real-time redo apply using "RA01" as the primary RA and "RA02" as the alternate.
NOTE: Real-time redo isn't mandatory to use but it makes the switching over of redo a lot easier. I will show how the environment looks with real-time redo. if you are manually sending archive logs and level 0 backups, the flow will be similar.
Real-time Redo flow
First lets take a look at the configuration for real-time redo.
Below is the configuration for a database with both a primary and and alternate ZDLRA. Working with an alternate destination is well described in this blog post.
Primary ZDLRA (RA01) configuration
LOG_ARCHIVE_DEST_3=“SERVICE=<"RA01" string from wallet>”, VALID_FOR=(ALL_LOGFILES, ALL_ROLES) ASYNC DB_UNIQUE_NAME=’<"RA01" ZDLRA DB>’ noreopen alternate=log_archive_dest_4;
log_archive_dest_state_3=enable;
Alternate ZDLRA (RA02) configuration
LOG_ARCHIVE_DEST_4=“SERVICE=<"RA02" string from wallet>”, VALID_FOR=(ALL_LOGFILES, ALL_ROLES) ASYNC DB_UNIQUE_NAME=’<"RA02" ZDLRA DB> ;
LOG_ARCHIVE_STATE__4=alternate;
Below is what the flow looks like.
Redo log traffic and backups are sent from "PROTDB" to "RA01". "RA02" (since it is the upstream pair of "RA01") is aware of the backups in it's RMAN catalog.

Now let's take a look at the status of the destinations
SQL> select dest_id, dest_name, status from
v$archive_dest_status where status <> 'INACTIVE';
DEST_ID DEST_NAME STATUS
---------- --------------------- ---------
1 LOG_ARCHIVE_DEST_3 VALID
2 LOG_ARCHIVE_DEST_4 UNKNOWN
You can see that the redo logs are sent to DEST_3 ("RA01") and DEST_4 ("RA02") is not active.
Now lets see what happens when "RA01" can't be reached.
SQL> select dest_id, dest_name, status from
v$archive_dest_status where status <> 'INACTIVE';
DEST_ID DEST_NAME STATUS
---------- --------------------- ---------
1 LOG_ARCHIVE_DEST_3 DISABLED
2 LOG_ARCHIVE_DEST_4 VALID
After the second failed attempt, the original destination is marked as disabled, and the alternate is valid.
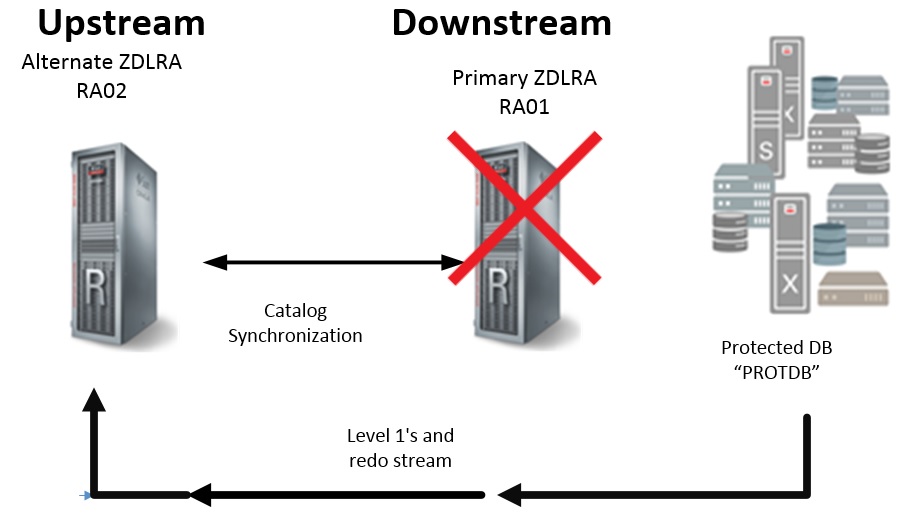
Below you can see that the redo logs, and the backups (Level 1) are being sent to "RA02".
"PROTDB" connects to the catalog on "RA02" which is aware of the previous backups and synchronizes its backup information with the control file.
This allows the next Level 1 incremental backup to be aware of the most current virtual full backup on "RA01".
This also allows the redo log stream to continue where it left off with "RA01". The RMAN catalog on "RA02" is aware of all redo logs backups on "RA01" and is able to continue with the next log.
Now lets see what happens when "RA01" becomes available.
When "RA01" becomes available, you start the replication flow downstream. This will allow all the backups (redo and/or Level 1) to replicate to "RA01", be applied to the RA, and update the RMAN catalog.
Once this complete, RA01 will have virtualized any backups, along with storing and cataloging all redo logs captured.

BUT, at this point the primary log destination is still disabled so we need to renable it to start the redo log flow back.
SQL> alter system set log_archive_dest_state_3=enable;
System altered.
SQL> alter system set log_archive_dest_state_4=alternate;
System altered.
Once this is complete. We are back to where we started.

That's it.
Store-and-forward is a great HA solution for capturing real-time redo log information to absorb any hiccups that may occur.