When working on my latest project, I wanted to be able to provide an easy web interface that can be used to upload images into OCI object storage on ZFSSA by choosing the file on my local file system.
In this blog post, I will go through the series of steps I used to create a page in my APEX application that allows a user to choose a local file on their PC, and upload that file (image in my case) to OCI object storage on ZFSSA.
Below are the series of steps I followed.
Configure ZFSSA as OCI object storage
First you need to configure your ZFSSA as OCI object storage. Below are a couple of links to get you started.
During this step you will
- Create a user on ZFSSA that will be be the owner of the object storage
- Add a share that is owned by the object storage user
- Enable OCI API mode "Read/Write" as the protocol for this share
- Under the HTTP service enable the service and enable OCI.
- Set the default path as the share.
- Add a public key for the object storage user under "Keys" within the OCI configuration.
NOTE: You can find an example of how to create public/private key pair
here.
Create a bucket in the OCI object storage on ZFSSA
In order to create a bucket in the OCI object storage you need to use the "OCI cli" interface.
If you have not installed it already, you can use
this link for instructions on how to install it.
Once installed, you need to configure the ~/.oci/config file and I explain the contents in my "OCI access to ZFS" section of
this blog post.Now you should have the oci cli installed, and the configuration file created, and we are ready for the command to create the bucket.
oci os bucket create --endpoint http:{ZFSSA name or IP address} --namespace-name {share name} --compartment-id {share name} --name {bucket name}
For my example below:
| Parameter |
value |
| ZFSSA name or IP address |
zfstest-adm-a.dbsubnet.bgrennvcn.oraclevcn.com |
| share name |
objectstorage |
| bucket name |
newobjects |
The command to create my bucket would is:
oci os bucket create --endpoint http://zfstest-adm-a.dbsubnet.bgrennvcn.oraclevcn.com --namespace-name objectstorage --compartment-id objectstorage --name newobjects
Ensure you have the authentication information for APEX
This step is to make sure you have what you need for APEX in order to configure and upload an object into object storage on ZFSSA.
If you successfully created a bucket in the last step, you should have everything you need in the configuration file that you used. Looking at the contents of my config file (below) I have almost all the parameters I need for APEX.
From the step above I have the correct URL to access the object storage and the bucket.
http://{ZFSSA name or IP address}/n/{share name}/b/{bucket name}/o/
which becomes
http://zfstest-adm-a.dbsubnet.bgrennvcn.oraclevcn.com/n/objectstorage/newobjects/o/
The rest of the information except for tenancy is in the configuration file.
| Parameter in config file |
value |
| user |
ocid1.user.oc1..{ZFS user} ==> ocid1.user.oc1..oracle |
| fingerprint |
{my fingerprint} ==> 88:bf:b8:95:c0:0a:8c:a7:ed:55:dd:14:4f:c4:1b:3e |
| key_file |
This file contains the private key, and we will use this in APEX |
| region |
This is always us-phoenix-1 and is |
| namespace |
share name ==> objectstorage |
compartment
| | share name ==> objectstorage |
|
NOTE: The tenancy ID for ZFSSA is always "ocid1.tenancy.oc1..nobody"
In APEX configure web credentials
Now that we have all of the authentication information outlined in the previous step, we need to configure web credentials to access the OCI object storage on ZFSSA as a rest service.
In order to add the web credentials I log into my workspace in APEX. Note I am added the credentials at the workspace level rather than at the application level.
Within your workspace make sure you are within the "App Builder" section and click on "Workspace Utilities".
Within "Workspace Utilities" click on "web Credentials".
Now click on "Create >" to create new web credential
Enter the information below (also see screen shot)
- Name of credential
- Type is OCI
- user Id from above
- private key from above
- Tenancy ID is always ocid1.tenancy.oci1..nobody for ZFSSA
- Fingerprint that matches the public/private key
- URL for the ZFS
In apex create the upload region and file selector
I have an existing application, or you can create a new application in apex. I am going to start by creating a blank page in my application.
After clicking on "Next >", I give the new page a name and create the page.
Then on the new page I created a new region by right clicking on "Body"
Once I created the region, I named the region "upload" by changing the identification on the right hand side of Page Designer.
Then on the left hand side of Page Designer, I right clicked on my region "upload" and chose to create a new "Page Item".
After creating the new page item I needed to give the item a better identification name and change the type to "file upload". See the screen shot below.
In apex create the Button to submit the file to be stored in object storage.
Next we need to add a button to upload the file to object storage. Right click on the "upload" region, and this time choose "create button below".
I gave the button a clearer name to identify what it's there for
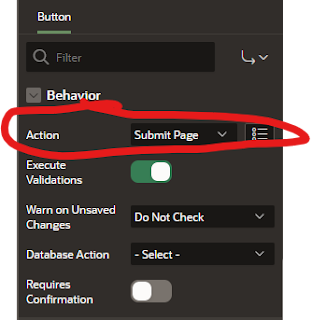
And I scrolled down the attributes of the button on the right hand side, and made sure that the behavior for the button was "Submit Page"
In apex add the upload process itself
Click on the processing section in the top left corner of Page Designing and you will see the sections for page process. Right click on "Processing" and click on "Create process"
The next step is to give the process a better identifier, and I named my "file_upload", and I also need to include the PL/SQL code to execute as part of this process.
The items we need to customer for the code snippet are.
| ITEM |
VALUE |
| File Browse Page Item |
":" followed by the name of the file selector. Mine is ":FILE_NAME" |
| Object Storage URL |
This is the whole URL including namespace and bucket name |
| Web Credentials |
This is the name for the Web Credentials created for the workspace |
My PL/SQL code is below with the values I've mentioned throughout this blog.
declare
l_request_url varchar(32000);
l_content_length number;
l_response clob;
upload_failed_exception exception;
l_request_object blob;
l_request_filename varchar2(500);
begin
select blob_content, filename into l_request_object, l_request_filename from apex_application_temp_files where name = :FILE_NAME;
l_request_url := 'http://zfstest-adm-a.dbsubnet.bgrennvcn.oraclevcn.com/n/objectstorage/b/newobjects/o/' || apex_util.url_encode(l_request_filename);
l_response := apex_web_service.make_rest_request(
p_url => l_request_url,
p_http_method => 'PUT',
p_body_blob => l_request_object,
p_credential_static_id => 'ZFSAPI'
);end;
In the APEX database ensure you grant access to the URL
The final step before we test this is to add the ACL grant for the URL.
NOTE: This needs to be granted to to the apex application owner, in my case APEX_230200
BEGIN
DBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(
host => '*',
ace => xs$ace_type(privilege_list => xs$name_list('connect', 'resolve'),
principal_name => 'APEX_230200',
principal_type => xs_acl.ptype_db
)
);
END;
/
Upload the object and verify it was successful
After saving the page in Page Designer run the page to upload an object.
Choose an object from your local file system and click on the "Upload Object" button.
If there were no errors, it was successful and you can verify it was uploaded by listing the objects in the bucket.
Below is my statement to list the objects.
oci os object list --endpoint http://zfstest-adm-a.dbsubnet.bgrennvcn.oraclevcn.com --namespace-name objectstorage --bucket-name newobjects
That's all there is to it















































