If you have been wondering why I've spent so much time blogging about how to configure ZFS as an object store, today is the day you get the answer.

Today MOS note 2748362.1 - How To Setup And Use DBMS_CLOUD Package was published.
You are probably saying, "so what?, 21c supports DBMS_CLOUD, and that's a long way off for me"..
This note goes through the steps to configure DBMS_CLOUD for 19c. Yes. it's backported !
NOTE: it is only supported for multitenant
If you were very astute, you might have noticed that the 19.9 release of the software contained scripts in the $ORACLE_HOME/rdbms/admin directory with names like dbms_cloud.sql.
Well today, this published notes explains how to install DBMS_CLOUD packages so that you can use it with your 19.9 + database.
I'm going to take this a step further, and show you how to use these scripts and connect the ZFS appliance. Keep in mind, there is a ZFS simulator you can use, and do the same steps.
Here is some information on how to do this if you don't know where to start
Configuring ZFS as an object store
Step 1. Install DBMS_CLOUD in the CDB
I am going through the MOS, and I am following the same series of steps. Creating a script in my /home/oracle/dbc directory, so that I can run this again for all my databases.
Just as in the note, I ran a perl script, and looked at the logs. Everything was successful.
I then ran the 2 queries. First against the CDB, then against the PDB.
So far so good.
Step 2 Create SSL Wallet with Certificates.
The next step is to create a wallet, and download the certificates using the link. The certificates come in a zip file containing all 3 certificates.
BaltimoreCyberTrust.cer
DigiCert.cer
These are the Certificate Authorities that will be used to authenticate the SSL certificates. DBMS_CLOUD uses HTTPS, and requires that a valid certificate is used.
ZFS NOTE BEGIN : *************************************
At this point there is an additional step for using ZFS (or your own object store). You need to add the certificate to the wallet if it is a self-signed certificate (which is what ZFS will use normally).
In order to get the certificate you need to display it with the following command (filling in your IP address).
openssl s_client -showcerts -connect 10.136.64.85:443
From the output I want to grab the certificate which is between the BEGIN and END
-----BEGIN CERTIFICATE-----
MIIEWTCCA0GgAwIBAgIIXJAYBgAAAA
AwwkenM3LTJjYXAtMjAwZi12bTAyLn
DDZodHRwczovL3pzNy0yY2FwLTIwMG
..
oH4pa4Hv4/
-----END CERTIFICATE-----
Once I put it in a file, I perform the same command to load these certificates from my file.
ZFS NOTE END : *****************************************
Once added I display what is in the wallet.
orapki wallet display -wallet .
Oracle PKI Tool Release 21.0.0.0.0 - Production
Version 21.0.0.0.0
Copyright (c) 2004, 2020, Oracle and/or its affiliates. All rights reserved.
Requested Certificates:
User Certificates:
Trusted Certificates:
Subject: 2.5.4.13=https://zs7-2cap-200f-vm02.bgrenn.com:215/\#cert,CN=zs7-2cap-200f-vm02.bgrenn.com
Subject: 2.5.4.13=https://zs7-2cap-200f-vm01.bgrenn.com:215/\#cert,CN=zs7-2cap-200f-vm01.bgrenn.com
Subject: CN=DigiCert Global Root CA,OU=www.digicert.com,O=DigiCert Inc,C=US
Subject: CN=Baltimore CyberTrust Root,OU=CyberTrust,O=Baltimore,C=IE
Subject: CN=VeriSign Class 3 Public Primary Certification Authority - G5,OU=(c) 2006 VeriSign\, Inc. - For authorized use only,OU=VeriSign Trust Network,O=VeriSign\, Inc.,C=US
You can see that it captured the server names of the ZFS ports I am using.
Step 3 Configure the Oracle environment for the Wallet.
- I am in a RAC environment so I need to make the change to ALL nodes in my RAC cluster, and I also need to copy the wallet to the nodes in the same location on all hosts.
- The WALLET_LOCATION is also used by ZDLRA. if you are using a ZDLRA for backups, you need add the certificates to wallet that is used by the ZDLRA.
- If you using Single Sign On which may use the WALLET_LOCATION, be especially careful since they often default to $ORACLE_BASE, but will get over ridden when this is set.
Step 4 Configure the Database with ACEs for DBMS_CLOUD.
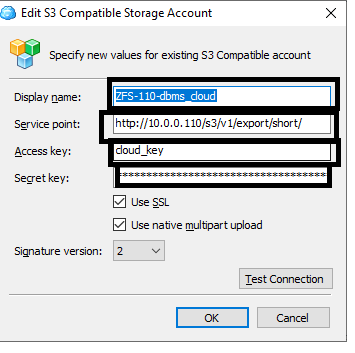
- define sslwalletdir= {my wallet locatioin} --> I set this.
- I removed all lines around proxy. I didn't need a proxy since I am only using a ZFS internal to my datacenter.
Step 5 Verify the configuration of the DBMS_CLOUD
- wallet_path => {my wallet path}
- wallet_password => {my wallet password}
- get_page('https://zs7-2cap-200f-vm02.bgrenn.com') --> I put in the URL for my first ZFS network name (from the certificate) followed by the second name from the certificate.
SELECT host, lower_port, upper_port, acl FROM dba_network_acls;
Step 6 Configure users or roles to use DBMS_CLOUD
Step 6 Configure users or roles to use DBMS_CLOUD
Step 7 Configure ACEs for a user role to use DBMS_CLOUD
Step 8 Configure the credential for OCI (or S3 if you prefer).
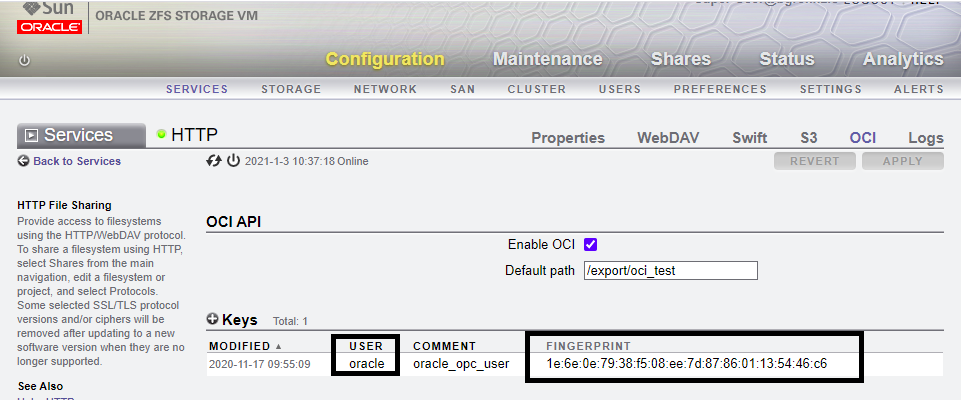
exec DBMS_CLOUD.CREATE_CREDENTIAL ( -
CREDENTIAL_NAME => 'ZFS', -
USER_OCID => 'ocid1.user.oc1..oracle', -
TENANCY_OCID => 'ocid1.tenancy.oc1..nobody', -
PRIVATE_KEY => 'MIIEogIBAAKCAQEAnLe/u2YjNVac5z1j/Ce7YRSd6wpwaK8elS+TxucaLz32jUaDCUfMbzfSBP0WK00uxbdnRdUAss1F1sRUm+GqyEEvT2c1LRJ0FnfSFEXrJnDZfEVe/dFi90fctbx4BUSqRroh0RQbQyk24710zO2C3tev66eHEvfxxXGUqI+jrDKOJ7sFdGE42R9uRhhWxaWS4e43OEZk41gq2ykdVFlNp...mXU6w6blGpxWkzfPMJKuOhXYoEXM41uxykDX3nq/wPWxKJ7TnShGLyiFMWiuuQF+s29AbwtlAkQRcHnnkvDFHwE=', -
FINGERPRINT => '1e:6e:0e:79:38:f5:08:ee:7d:87:86:01:13:54:46:c6');
Note the parameters for ZFS
- CREDENTIAL_NAME - Name of the credential
- USER_OCID - 'ocid1.user.oci..' || {ZFS user id}
- TENANCY_ID - 'ocid1.tenancy.oci1..nobody' - hardocded in
- PRIVATE_KEY - Private key matching the public key on the ZFS
- FINGERPRINT - fingerprint for the public key on the ZFS.
Step 9 Load raw data to the object store.
16TS$ TABLE 1904172019041720190417VALID
20ICOL$ TABLE 1904172019041720190417VALID
8C_FILE#_BLOCK# CLUSTER 1904172019041720190417VALID
37I_OBJ2 INDEX 1904172019041720190417VALID
22USER$ TABLE 1904172019041720190417VALID
33I_TAB1 INDEX 1904172019041720190417VALID
40I_OBJ5 INDEX 1904172019041720190417VALID
31CDEF$ TABLE 1904172019041720190417VALID
41I_IND1 INDEX 1904172019041720190417VALID
3I_OBJ# INDEX 1904172019041720190417VALID
6C_TS# CLUSTER 1904172019041720190417VALID
51I_CON1 INDEX 1904172019041720190417VALID
34I_UNDO1 INDEX 1904172019041720190417VALID
11I_USER# INDEX 1904172019041720190417VALID
29C_COBJ# CLUSTER 1904172019041720190417VALID
49I_COL2 INDEX 1904172019041720190417VALID
32CCOL$ TABLE 1904172019041720190417VALID
14SEG$ TABLE 1904172019041720190417VALID
23PROXY_DATA$ TABLE 1904172019041720190417VALID
44I_FILE2 INDEX 1904172019041720190417VALID
46I_USER1 INDEX 1904172019041720190417VALID
56I_CDEF4 INDEX 1904172019041720190417VALID
21COL$ TABLE 1904172019041720190417VALID
47I_USER2 INDEX 1904172019041720190417VALID
26I_PROXY_ROLE_DATA$_1 INDEX 1904172019041720190417VALID
18OBJ$ TABLE 1904172019041720190417VALID
42I_ICOL1 INDEX 1904172019041720190417VALID
19IND$ TABLE 1904172019041720190417VALID
39I_OBJ4 INDEX 1904172019041720190417VALID
59BOOTSTRAP$ TABLE 1904172019041720190417VALID
36I_OBJ1 INDEX 1904172019041720190417VALID
15UNDO$ TABLE 1904172019041720190417VALID
10C_USER# CLUSTER 1904172019041720190417VALID
4TAB$ TABLE 1904172019041720190417VALID
2C_OBJ# CLUSTER 1904172019041720190417VALID
28CON$ TABLE 1904172019041720190417VALID
5CLU$ TABLE 1904172019041720190417VALID
27I_PROXY_ROLE_DATA$_2 INDEX 1904172019041720190417VALID
24I_PROXY_DATA$ INDEX 1904172019041720190417VALID
45I_TS1 INDEX 1904172019041720190417VALID
13UET$ TABLE 1904172019041720190417VALID
12FET$ TABLE 1904172019041720190417VALID
17FILE$ TABLE 1904172019041720190417VALID
Step 10 Create an external table on the object.
ERROR at line 1:
ORA-20006: Unsupported object store URI -
https://zs7-2cap-200f-vm01.bgrenn.oracle.com/export/objectstoreoci/bucketoci
/objects.csv
ORA-06512: at "C##CLOUD$SERVICE.DBMS_CLOUD", line 917
ORA-06512: at "C##CLOUD$SERVICE.DBMS_CLOUD", line 2411
ORA-06512: at line 1
- CLOUD_TYPE - authentication to use
- BASE_URI_PATTERN - URI pattern to identify and allow
- VERSION - This is used if different authentication versions exist for an object store
- STATUS - Not sure, but they are all '1'
desc C##CLOUD$SERVICE.dbms_cloud_store;
Name Null? Type
----------------------------------------- -------- ----------------------------
CLOUD_TYPE VARCHAR2(128)
BASE_URI_PATTERN VARCHAR2(4000)
VERSION VARCHAR2(128)
STATUS NUMBER
SQL> insert into C##CLOUD$SERVICE.dbms_cloud_store values ('ORACLE_BMC','%.bgrenn.com',null,1);
1 row created.
SQL> commit;
Commit complete.
exec DBMS_CLOUD.CREATE_EXTERNAL_TABLE( -
table_name =>'CHANNELS_EXT_ZFS', -
credential_name =>'ZFS', -
file_uri_list =>'https://zs7-2cap-200f-vm01.bgrenn.com/oci/n/export/objectstoreoci/b/bucketoci/o/objects.csv', -
format => json_object('trimspaces' value 'rtrim', 'skipheaders' value '1', 'dateformat' value 'YYYYMMDD'), -
field_list => 'object_id (1:10) char' || -
', object_name (11:40) char' || -
', object_type (41:65) char' || -
', created_date1 (66:71) date mask "YYMMDD"' || -
', created_date2 (72:79) date' || -
', last_ddl_time (80:87) date' || -
', status (88:97)', -
column_list => 'object_id number' || -
', object_name varchar2(30)' || -
', object_type varchar2(25)' || -
', status varchar2(10)' || -
', created_date1 date' || -
', created_date2 date' || -
', last_ddl_time date');
OBJECT_ID OBJECT_NAME OBJECT_TYPE STATUS
---------- ------------------------------ ------------------------- ----------
CREATED_D CREATED_D LAST_DDL_
--------- --------- ---------
20 ICOL$ TABLE VALID
17-APR-19 17-APR-19 17-APR-19
8 C_FILE#_BLOCK# CLUSTER VALID
17-APR-19 17-APR-19 17-APR-19
37 I_OBJ2 INDEX VALID
17-APR-19 17-APR-19 17-APR-19