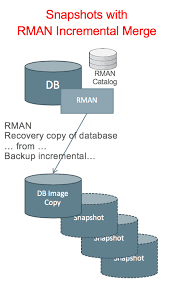
In the last couple of years I have seen a lot of backup vendors (Commvault, Netbackup, Rubrik etc.) using the incremental merge backup process that Oracle introduced in 10G.
These vendors have combined the incremental merge with snapshots of each new merged backup to provide a daily restore point. The process is to perform an incremental backup, use the DB software to merge in the changes, and then "snap" the storage. Rinse and repeat.
The archive logs are also backed up to provide a recovery point in time.
This process has a few flaws.
- You are leveraging DB resources to perform the merge. Only the DB software knows the proprietary format of files to merge in the changes.
- The merge process is a sequential process that can be slow. You are essentially "recovering" the database one day forward using the merge process. We all know how slow a recovery can be.
- The storage used for these backups is typically not tier 1 storage, and this also affects the speed of the merge process.
- The RMAN catalog only knows about the last incremental merge. In order to recover to more than the last merge, you need to catalog the older backups.
- These are FULL SIZE datafile copies. RMAN backup sets have many features to optimize the size of backupsets (exclude unused blocks, compress, etc.) that can't be leveraged with this type of backups.
- Lastly, there is no inherent checking of backups for corruption. If there is any corruption in the backup, it may not be found.
I am going walk through an example showing you the last point.
But first, I want to point out how the ZDLRA addresses all of these points.
But first, I want to point out how the ZDLRA addresses all of these points.
- The ZDLRA uses the same proprietary software that RMAN uses to merge in the changes. Rather than using DB resources (and licensed CPUs) to merge in the changes, the ZDLRA offloads this workload and performs the merge internally
- The ZDLRA simply keeps track of block changes and indexes them. This process is much more efficient than a recovery process, and scales much better.
- The ZDLRA uses tier 1 storage and flash allowing the performance to match or exceed that of the databases it is protecting
- The RMAN catalog is within the ZDLRA allowing it to automatically catalog new full backups as they are created.
- These are backupsets, and don't include unused space optimizing space utilization.
- There are many layers of error checking. This includes not only during the backup, but also within the ZDLRA (and when replicated). The ZDLRA offloads the "restore validate" process to ensure that DB blocks that haven't been touched for a long time are periodically checked for corruption. An "incremental forever" strategy is risky if you don't periodically check blocks for corruption.
Now to show why periodically checking for corruption is so important.
I am going to schedule an incremental merge of a single datafile (to keep it simple), inject corruption into the datafile copy, and then continue to merge into the backup.
I am going to schedule an incremental merge of a single datafile (to keep it simple), inject corruption into the datafile copy, and then continue to merge into the backup.
First, I'm going to create a new tablespace for my testing.
SYS:DB10 > create tablespace bsg datafile '/tmp/bsg.dbf' size 10m;
Tablespace created.
Now that we have a tablespace, let's create a table in the tablespace that we can use to provide corruption.
create table corruption_test tablespace bsg as select * from dba_users;
Table created.
SQL> select file_id, block_id from dba_extents where segment_name = 'CORRUPTION_TEST';
FILE_ID BLOCK_ID
---------- ----------
16 128
Now I have a copy of dba_users in my new tablespace, and I know where the data is.
I am going run my script (below) and perform a couple of incremental merges.
run
{
allocate channel disk1 device type disk format '/tmp/bkup%U';
recover copy of datafile 16 with tag 'incr_merge';
backup incremental level 1 for recover of copy with tag 'incr_merge' datafile 16;
}
Now here is the output, everything looks good. I backed it up, and the changes are getting merged into the image copy of the datafile.
Starting recover at 08/27/19 17:05:00
no copy of datafile 16 found to recover
Finished recover at 08/27/19 17:05:00
Starting backup at 08/27/19 17:05:00
channel disk1: starting incremental level 1 datafile backup set
channel disk1: specifying datafile(s) in backup set
input datafile file number=00016 name=/home/oracle/app/oracle/oradata/BSG18/bsg.dbf
channel disk1: starting piece 1 at 08/27/19 17:05:01
channel disk1: finished piece 1 at 08/27/19 17:05:02
piece handle=/tmp/bkup52ua97lt_1_1 tag=INCR_MERGE comment=NONE
channel disk1: backup set complete, elapsed time: 00:00:01
Finished backup at 08/27/19 17:05:02
Starting Control File and SPFILE Autobackup at 08/27/19 17:02:49
piece handle=/home/oracle/app/oracle/fast_recovery_area/bsg18/BSG18/autobackup/2019_08_27/o1_mf_s_1017421369_gpc6mt45_.bkp comment=NONE
Finished Control File and SPFILE Autobackup at 08/27/19 17:02:52
released channel: disk1
RMAN> run
{
allocate channel disk1 device type disk format '/tmp/bkup%U';
recover copy of datafile 16 with tag 'incr_merge';
backup incremental level 1 for recover of copy with tag 'incr_merge' datafile 16;
}
Starting recover at 08/27/19 17:07:35
channel disk1: starting incremental datafile backup set restore
channel disk1: specifying datafile copies to recover
recovering datafile copy file number=00016 name=/tmp/bkupdata_D-BSG18_I-101380451_TS-BSG_FNO-16_4vua97ho
channel disk1: reading from backup piece /tmp/bkup52ua97lt_1_1
channel disk1: piece handle=/tmp/bkup52ua97lt_1_1 tag=INCR_MERGE_BSG
channel disk1: restored backup piece 1
channel disk1: restore complete, elapsed time: 00:00:01
Finished recover at 08/27/19 17:07:37
Starting backup at 08/27/19 17:07:37
channel disk1: starting incremental level 1 datafile backup set
channel disk1: specifying datafile(s) in backup set
input datafile file number=00016 name=/home/oracle/app/oracle/oradata/BSG18/bsg.dbf
channel disk1: starting piece 1 at 08/27/19 17:07:37
channel disk1: finished piece 1 at 08/27/19 17:07:38
piece handle=/tmp/bkup54ua97qp_1_1 tag=INCR_MERGE_BSG comment=NONE
channel disk1: backup set complete, elapsed time: 00:00:01
Finished backup at 08/27/19 17:07:38
I am going to use "sed" and change the user "SYSTEM" to " " in the image copy of the datafile.
oracle@/tmp [18c] $ sed -i 's/SYSTEM/ /g' /tmp/bkupdata_D-BSG18_I-101380451_TS-BSG_FNO-16_4vua97ho
Now I'm going to run the same incremental merge again (and again).
Here's the output.. everything looks fine since I didn't touch the block that is corrupted.
The merge process is simply replacing blocks that have changed.
Starting recover at 08/27/19 17:13:05
channel disk1: starting incremental datafile backup set restore
channel disk1: specifying datafile copies to recover
recovering datafile copy file number=00016 name=/tmp/bkupdata_D-BSG18_I-101380451_TS-BSG_FNO-16_4vua97ho
channel disk1: reading from backup piece /tmp/bkup54ua97qp_1_1
channel disk1: piece handle=/tmp/bkup54ua97qp_1_1 tag=INCR_MERGE
channel disk1: restored backup piece 1
channel disk1: restore complete, elapsed time: 00:00:01
Finished recover at 08/27/19 17:13:07
Starting backup at 08/27/19 17:13:07
channel disk1: starting incremental level 1 datafile backup set
channel disk1: specifying datafile(s) in backup set
input datafile file number=00016 name=/home/oracle/app/oracle/oradata/BSG18/bsg.dbf
channel disk1: starting piece 1 at 08/27/19 17:13:07
channel disk1: finished piece 1 at 08/27/19 17:13:08
piece handle=/tmp/bkup56ua9853_1_1 tag=INCR_MERGE comment=NONE
channel disk1: backup set complete, elapsed time: 00:00:01
Finished backup at 08/27/19 17:13:08
Now that I have performed some incremental merges, let's see what happens when I go to restore that datafile.
I took the datafile offline, removed it, and now will try to restore it from the image copy.
RMAN> alter database datafile 16 offline;
Statement processed
RMAN> exit
[oracle@oracle-server] rm /home/oracle/app/oracle/oradata/BSG18/bsg.dbf
[oracle@oracle-server] rman target /
RMAN> restore datafile 16;
Starting restore at 08/27/19 17:15:01
using target database control file instead of recovery catalog
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=30 device type=DISK
channel ORA_DISK_1: restoring datafile 00016
input datafile copy RECID=53 STAMP=1017421986 file name=/tmp/bkupdata_D-BSG18_I-101380451_TS-BSG_FNO-16_4vua97ho
destination for restore of datafile 00016: /home/oracle/app/oracle/oradata/BSG18/bsg.dbf
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: failure of restore command at 08/27/2019 17:15:02
ORA-19566: exceeded limit of 0 corrupt blocks for file /tmp/bkupdata_D-BSG18_I-101380451_TS-BSG_FNO-16_4vua97ho
ORA-19600: input file is datafile-copy 53 (/tmp/bkupdata_D-BSG18_I-101380451_TS-BSG_FNO-16_4vua97ho)
ORA-19601: output file is datafile 16 (/home/oracle/app/oracle/oradata/BSG18/bsg.dbf)
Now, even though the incremental merges all look good, the corruption isn't caught until I go to restore the datafile.
This is why it is so important to execute a restore validate on a regular basis, and keep a secondary backup.
With the incremental merge process, there is only 1 copy of each unique block. For historical data that doesn't change, those blocks will never get checked for corruption.