This blog post is on the immediate effect of implementing TDE in your database backup storage.
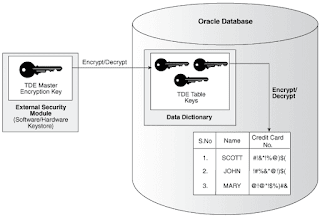
In the last blog post I mentioned that after implementing TDE you need to explicitly perform a full backup on all tablespaces you encrypt.

Using my example dataset for a just a weekly full backup and a daily incremental backup (using deduplication) you can see that
The data in my database is 35 GB ( the fully allocated size is 50 GB).
The amount of change over 30 days is 70 GB.
Compressing both of these, the final size is 41.5 GB used.
Prior to implementing TDE, I am using 41.5 consistently to store 30 days of compressed backups for my 50GB database.
The next column shows what happens when after implementing TDE. The full backup size compressed is now 43.9 GB and the amount of change over 30 days is 54 GB compressed.
After implementing TDE, I am using 97.9 GB consistently to store 30 days of compressed backups for my 50 GB database.
Now let's see what first 30 days looks like.
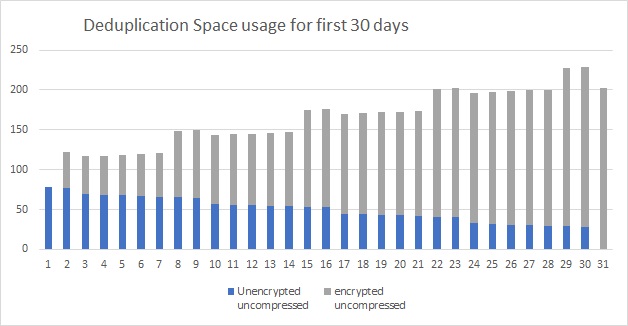
This shows the unencrypted backups (purple) and how they start to age off and get removed on day 31. You can also see how the encrypted backups (gray) grow over time and the will stabilize to the size you see on day 31.
You can see that there is an immediate impact to the backup usage. That growth continues until the old backup is finally ages off.
You need to plan for TDE ahead of time. For my example dataset, the storage needed more than doubled.

In the last blog post I mentioned that after implementing TDE you need to explicitly perform a full backup on all tablespaces you encrypt.
- If you are performing an incremental strategy (level 0 and level 1) then explicitly perform a level 0 backup.
- If you are using an incremental merge backup (BACKUP INCREMENTAL LEVEL 1 for RECOVERY of COPY), you must create a new image copy and start a new divergent backup
Above is the reason for this post. If you have an unencrypted database, and you implement TDE on all tablespaces, then perform a full backup of all tablespaces, you will have 2 copies of your backups for a period of time.
I am going to take a closer look at what this means to my backup storage when implementing TDE.
For my example, I'm going to use the same example I used in the last post.
Below is what it looks like.

Using my example dataset for a just a weekly full backup and a daily incremental backup (using deduplication) you can see that
The data in my database is 35 GB ( the fully allocated size is 50 GB).
The amount of change over 30 days is 70 GB.
Compressing both of these, the final size is 41.5 GB used.
Prior to implementing TDE, I am using 41.5 consistently to store 30 days of compressed backups for my 50GB database.
The next column shows what happens when after implementing TDE. The full backup size compressed is now 43.9 GB and the amount of change over 30 days is 54 GB compressed.
After implementing TDE, I am using 97.9 GB consistently to store 30 days of compressed backups for my 50 GB database.
Now let's see what first 30 days looks like.

This shows the unencrypted backups (purple) and how they start to age off and get removed on day 31. You can also see how the encrypted backups (gray) grow over time and the will stabilize to the size you see on day 31.
You can see that there is an immediate impact to the backup usage. That growth continues until the old backup is finally ages off.
You need to plan for TDE ahead of time. For my example dataset, the storage needed more than doubled.




